Multimodal Agents: When LLMs Open Their Eyes to the World
While text-based Large Language Models (LLMs) possess powerful logical reasoning capabilities, they are inherently “blind.” The vast majority of tasks in the real world—such as browsing the web, operating software, or interpreting charts—rely heavily on visual information. Therefore, upgrading LLMs into Multimodal Agents, allowing them to “open their eyes and see the world,” has become one of the most critical breakthroughs in the AI field today.
This post systematically reviews the technical evolution of multimodal agents: from the underlying vision architecture basics to the construction of Large Multimodal Models (LMMs), and finally to how they execute tasks in complex Web environments.
1. Vision Architecture Basics: How Do Models “See” Images?
To feed an image into a Transformer-based language model, the core problem is: ** How do we represent a 2D image as a 1D sequence of vectors (Token Embeddings)? **
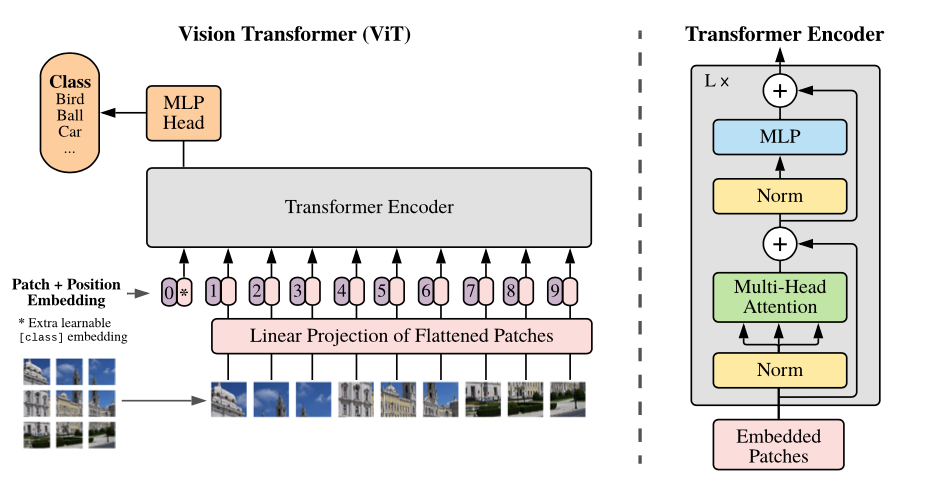
1.1 Vision Transformer (ViT)
The Vision Transformer (ViT), introduced in 2021, completely revolutionized computer vision. Its core idea is brutally simple: slice an image into multiple fixed-size patches (e.g., 16x16 pixels), flatten each patch, linearly project it into a vector, and feed the sequence directly into a standard Transformer.
1.2 Cross-Modal Alignment: CLIP and BLIP
Simply turning an image into vectors is not enough; we must ** align the image vectors and text vectors within the same semantic space **.
- ** CLIP (Contrastive Language-Image Pre-training) **: Before CLIP, image models were typically trained on manually annotated, fixed categories (like ImageNet’s 1000 classes). OpenAI broke this limitation by scraping 400 million image-text pairs directly from the internet.
-
** How it works **: CLIP consists of two independent neural networks: an ** Image Encoder ** (ResNet or ViT) and a ** Text Encoder ** (Transformer). During training, given a batch (e.g., 32,768 pairs), the model extracts 32,768 image vectors and 32,768 text vectors. It then computes the cosine similarity between all pairs, forming a $32768 \times 32768$ matrix.
-
** Contrastive Learning Objective **: Mathematically, CLIP optimizes a ** Symmetric InfoNCE Loss (Contrastive Cross-Entropy) **. Given a batch of $N$ image-text pairs, let $\boldsymbol{I}_i$ and $\boldsymbol{T}_i$ be the L2-normalized feature vectors of the $i$-th image and text, respectively. The model minimizes both the image-to-text and text-to-image contrastive losses:
$$ \mathcal{L}_{I \rightarrow T} = -\frac{1}{N} \sum_{i=1}^N \log \frac{\exp(\boldsymbol{I}_i \cdot \boldsymbol{T}_i / \tau)}{\sum_{j=1}^N \exp(\boldsymbol{I}_i \cdot \boldsymbol{T}_j / \tau)} $$Here, $\tau$ is a learnable temperature parameter. The essence of this formula is to maximize the numerator (the cosine similarity of true pairs on the diagonal) while minimizing the denominator (the penalty from all unpaired combinations in the matrix).
-
** The Zero-shot Miracle **: Because the text encoder has seen a massive variety of natural language descriptions, during inference, you simply convert all possible category names (e.g., “a cat”, “a car”) into text vectors, and see which text vector has the highest similarity to the input image vector. This allows the model to recognize objects it had never explicitly seen in a specific training set.
-
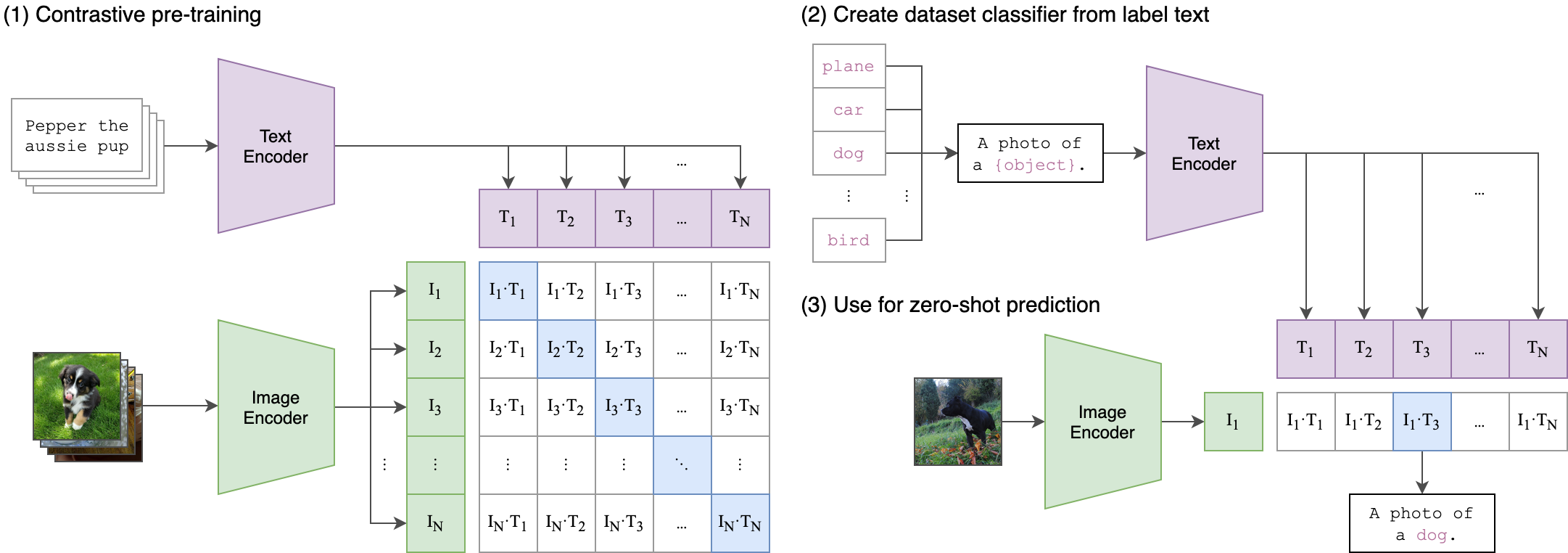
- ** BLIP (Bootstrapping Language-Image Pre-training) **: Although CLIP’s dual-encoder architecture (where the two encoders are completely independent and only interact via a dot product at the end) is extremely fast for retrieval, it lacks deep feature fusion, meaning ** it can only match, not generate **.
- ** Architecture Upgrade **: BLIP introduces a more complex cross-attention mechanism. It includes not only unimodal encoders but also an ** Image-Grounded Text Encoder ** (for deep image-text matching) and an ** Image-Grounded Text Decoder ** (for directly generating image captions).
- ** CapFilt Mechanism **: Internet image-text pairs are notoriously noisy (e.g., a picture of a dog captioned “Having a great weekend!”). BLIP’s core contribution is “bootstrapping”: it first uses the Decoder to generate synthetic captions for web images (Captioner), and then uses the Encoder to filter out noisy, mismatched data (Filter), resulting in an exceptionally clean training dataset.
2. Constructing Large Multimodal Models (LMMs)
Once we have a vision encoder, how do we integrate it with a powerful LLM? Currently, there are two main technical routes.
2.1 Non-native VLMs (The Stitching Approach)
This is currently the most common and cost-effective approach (e.g., LLaVA, Mini-GPT4). Because training a massive multimodal model from scratch is prohibitively expensive, researchers came up with a clever idea: directly “stitch” an existing vision model (like CLIP) and a language model (like Llama) together.
- Architecture: Image $\rightarrow$ Pre-trained Vision Encoder (extracts ViT vectors) $\rightarrow$ Projector $\rightarrow$ Powerful LLM.
- The Projector acts as a “translator.” Because the vision encoder outputs vectors in one dimension (e.g., 768-dim) and the LLM expects word embeddings in another (e.g., 4096-dim), and their semantic spaces are disconnected, the projector (usually a simple linear layer or MLP) translates visual signals into a “foreign language” the LLM can understand.
- Two-Stage Training Pipeline:
- Feature Alignment Stage: Freeze all parameters of both the vision encoder and the LLM, training only the thin intermediate Projector translator. The goal is to ensure that when the LLM sees an image vector, it can accurately output basic vocabulary (e.g., seeing a cat picture and outputting “cat”).
- Instruction Tuning Stage: Unfreeze the LLM (or use LoRA) and fine-tune the model using high-quality visual QA data (e.g., LLaVA-Instruct, which contains 150K manually constructed complex instruction examples). This step ensures the model doesn’t just recognize “this is a cat,” but can answer complex logical questions like “Why does this cat look angry?”
2.2 Native Multimodal Models
While the stitching approach is cheap, it has a fatal flaw: the vision encoder (like CLIP) acting as the “eyes” loses a lot of fine-grained information during pre-training because it was optimized for global matching. This makes stitched models notoriously bad at counting (e.g., counting the exact number of people in a crowd) or reading dense text in images (poor OCR capabilities). Thus, the industry has begun exploring LLMs trained from scratch using a mixture of multimodal data (e.g., the Qwen-VL family).
- Early Fusion vs. Late Fusion:
- The traditional stitching approach is considered Late Fusion, as the image is first “chewed” by a massive Vision Encoder to extract high-level features before being fed to the LLM.
- Early Fusion is far more radical: It completely abandons the independent vision encoder! Just like ViT, it slices the image into raw pixel patches, maps them via a minimalist linear layer, mixes them directly with text tokens, and feeds them all straight into the LLM, forcing the LLM to learn how to “see” by itself.
- Scaling Laws Discovery: Research from ICCV 2025 shows that at small parameter scales, models with independent vision encoders (Late Fusion) hold a slight advantage because the vision encoder provides good prior knowledge. However, at massive scales, Early Fusion and Late Fusion perform almost identically. This implies that in the future, we might not need a dedicated image encoder at all —a single, pure, unified Transformer could seamlessly handle data from all modalities.
3. Multimodal Agents in Action
Once an LMM acquires visual understanding, we can deploy it as an Agent to execute tasks within real Graphical User Interfaces (GUIs).
3.1 Why is Pure HTML Source Code Insufficient?
In early agent tests (like WebArena), Agents could only read the HTML source code (DOM tree) of web pages. But this approach has three fatal flaws:
- ** Extremely Messy Source Code **: Modern HTML is often minified and obfuscated by frontend frameworks, filled with meaningless nested
<div>tags. - ** Loss of Dynamic Interactions **: Many interactive elements (like hover-to-open menus or JavaScript-loaded popups) are simply not correctly represented in static HTML.
- ** Token Explosion **: The HTML source code of even a moderately complex webpage can easily exceed 100,000 tokens, severely depleting the LLM’s context window and inference compute.
Therefore, ** VisualWebArena ** introduced pure visual inputs. The Agent can directly “see” screenshots of the webpage. This not only drastically compresses the input information but also enables the Agent to handle purely visual tasks like “Does this used product have any cosmetic defects?”
3.2 The Visual Grounding Artifact: Set-of-Mark (SoM)
While multimodal models can understand webpage screenshots, if you command them to “click the shopping cart in the top right corner,” they struggle to output accurate screen coordinates (x, y). ** Because LLMs are fundamentally “language experts,” they are highly insensitive to continuous 2D spatial geometry coordinates. **
** Set-of-Mark (SoM) ** perfectly solves this problem: via a frontend script, it overlays numbered tags (Marks) directly onto all interactive elements (buttons, links, input fields) of a webpage screenshot. This way, the model doesn’t need to guess coordinates. It simply needs to output “** Click number 15 **” to achieve 100% accurate Visual Grounding. SoM ingeniously transforms a difficult “spatial geometry problem” into a “multiple-choice text problem” that LLMs excel at.
3.3 Agent Planning and Search: Tree Search
In real-world Web tasks, Agents frequently make mistakes, such as falling into infinite loops (oscillating between two pages) or giving up prematurely. Traditional single-thread reasoning (like ReAct) is like “walking through a maze blindfolded”—one wrong step leads to the “Local Decisions; Global Consequences” problem, where a local error causes global failure.
To address this, researchers introduced ** Tree Search ** mechanisms, giving the Agent a “regret pill”:
-
** Best-first search **: The Agent no longer follows a single path; it explores multiple branches simultaneously. If it realizes the current page is a dead end, it can perform ** Backtracking **, returning to the last correct page to select a different button.
-
** Value Function**: Faced with an exponentially exploding number of webpage navigation paths, a Value Function must be introduced to score and re-rank intermediate states. For example, evaluating “How far is the current page from buying the target product?”. Mathematically, given the current webpage state $s_t$, the Agent generates multiple candidate actions $a \in \mathcal{A}$. A Value Function $V(s)$ or State-Action Value $Q(s, a)$ scores each branch, guiding the Agent to prioritize exploring the path with the highest score:
$$ a^* = \arg\max_{a} Q(s_t, a) $$If the maximum expected value of the current state $s_t$ falls below a certain threshold, the Agent triggers the backtracking mechanism, abandoning the current dead end.
-
Core Challenge: Tree search is extremely slow. More fatally, many actions in real webpages are destructive/irreversible (e.g., you cannot simply click “Confirm Payment” or “Send Email” and then backtrack), which poses a massive challenge to the safe exploration of agents.
3.4 Breaking the Data Bottleneck: Internet-Scale Synthetic Training
Top LLMs still lag behind humans by nearly 69% on VisualWebArena. The core bottleneck is the lack of high-quality Agent interaction data. Recent research (like Towards Internet-Scale Training For Agents) proposes a brilliant solution: Use Llama to generate and verify synthetic tasks itself.
- Given a real web domain, ask the LLM to propose a reasonable task an average user might perform.
- Using this method, researchers generated massive amounts of synthetic trajectories across 150,000 live websites.
- Experiments prove that adding this synthetic data doubles the Agent’s generalization ability and task success rate (+156%).
Conclusion
Multimodal Agents are undergoing a metamorphosis from “text-blind” to “visual polymaths.” From the foundational ViT and CLIP, to non-native and native multimodal large models, and finally to Web Agents equipped with Set-of-Mark visual grounding and Tree Search.
Although Agents still face significant challenges in long-horizon planning and irreversible operations, with the explosive growth of synthetic data and the unification of underlying architectures, we are bound to see general multimodal assistants capable of proficiently operating Photoshop, Excel, and autonomously completing complex online shopping in the near future.