Breaking GPU Hardware Limits: Micro-benchmark Methodology, PTX Assembly, and Hopper Architecture
In the previous article, we explored the CUDA compilation toolchain, Warp scheduling mechanisms, and how to use Nsight Compute for performance bottleneck analysis.
As the second and final part of the CUDA Micro-benchmark series, we will dive deep into Methodology and Low-level Architecture. We will explore how to write test cases that push the GPU’s Arithmetic Logic Units (ALUs) and memory bandwidth to their absolute limits, understand complex memory consistency models, and provide a practical guide to avoiding pitfalls in PTX inline assembly. Finally, we will take a glimpse at the revolutionary asynchronous computing features brought by NVIDIA’s latest Hopper architecture (H100).
1. Pushing Hardware Limits: Compute and Bandwidth Methodology
1.1 Ultimate Compute (FLOPS) of ALUs
A GPU’s computing power is typically measured in FLOPS (Floating-Point Operations Per Second). For FP32 (single-precision floating-point), the theoretical compute limit is calculated as:
|
|
Note: FMA (Fused Multiply-Add) instructions can complete one multiplication and one addition (i.e., 2 floating-point operations) in a single clock cycle.
Testing Methodology and Pitfalls: To measure the ultimate compute, we usually write a kernel containing a massive number of FMA instructions (e.g., unrolling loops using inline PTX).
- FP16 Testing: Use
16x2instructions (likeHFMA2) to process two half-precision floats simultaneously. - 💡 Performance Optimization Tips: To keep the ALUs fully loaded and reach peak theoretical compute, you must use enough independent registers to unroll the loop (Loop Unrolling). If there are data dependencies (Read-After-Write, RAW) between calculation results, the instruction pipeline will not be fully issued (Issue Stall), and you may only reach half of the theoretical compute.
1.2 Memory Bandwidth Testing
The theoretical bandwidth of Global Memory is calculated as:
|
|
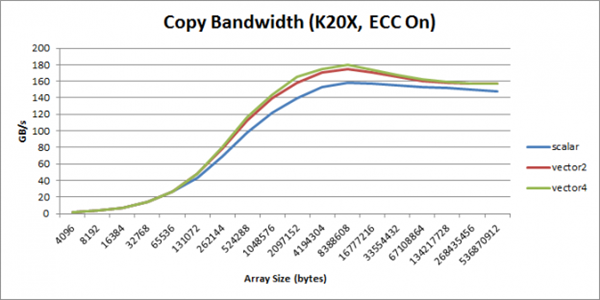
Testing Methodology and Vectorized Access: The most classic testing method is a Memory Copy between two memory segments. To achieve extremely high bandwidth utilization, it is highly recommended to use Vectorized Memory Access.
- Principle: Use built-in vector types like
int2,int4,float4. This exponentially reduces the number of memory access instructions issued (Issue Count), relieving pressure on the Warp Scheduler. - Example: Using
int2(8 bytes) for continuous copying:1reinterpret_cast<int2*>(d_out)[i] = reinterpret_cast<int2*>(d_in)[i];
2. Deep Dive into Memory Hierarchy and Consistency
2.1 Physical Characteristics of Global Memory and Caches (L1/L2)
The hierarchical logic for an SM (Streaming Multiprocessor) accessing global memory is: first access L1 Cache $\rightarrow$ if Miss, access L2 Cache $\rightarrow$ if still Miss, access DRAM (VRAM).
- Broadcast and Coalescing in Global Memory:
- Broadcast: When multiple Threads access the exact same address, it can be completed in a single memory transaction, broadcasting the data to all requesting Threads.
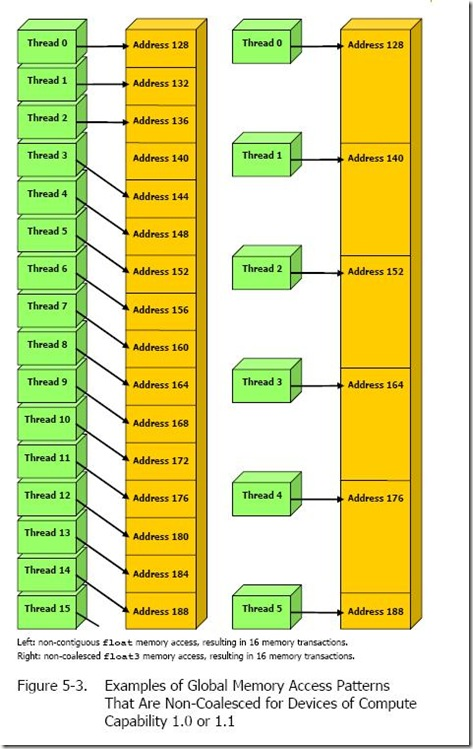
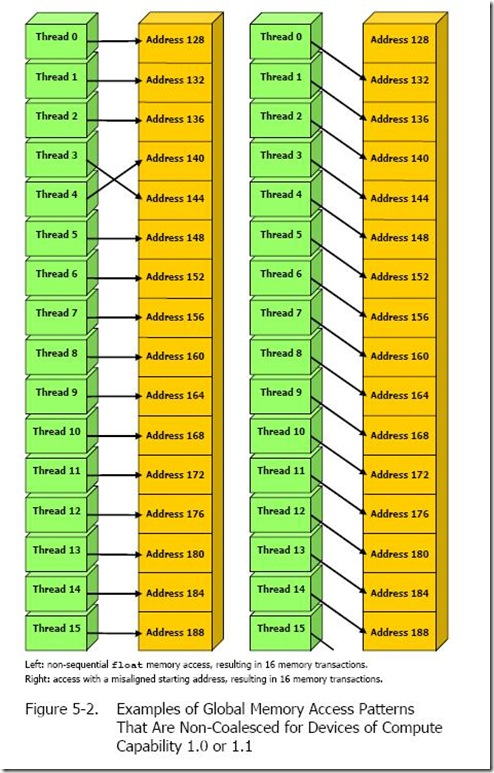
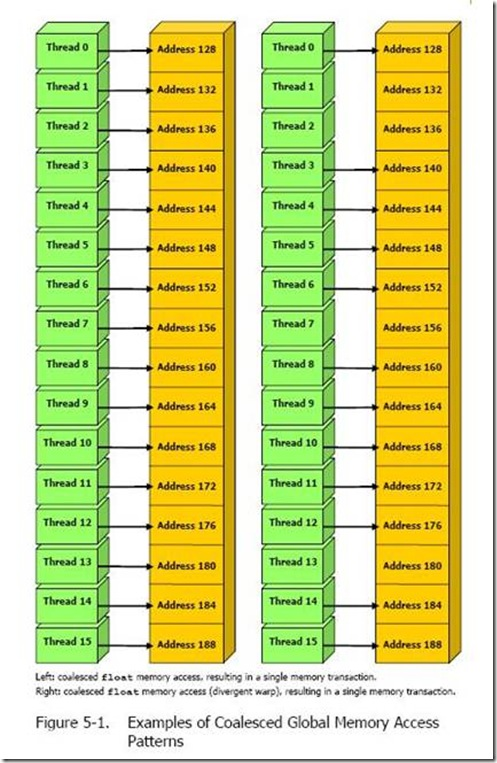
- Coalesced Access: The 32 Threads within a Warp must access continuous and aligned memory addresses to merge them into a single memory transaction (typically 32/64/128 Bytes), thereby maximizing bandwidth.
- L1 Cache: The read granularity (Cache Line) is 128 Bytes. Memory alignment addresses are best kept as multiples of 128 Bytes; and a Warp should ideally access 128 Bytes of continuous data at once (achieving 100% bandwidth utilization).
- L2 Cache: The read granularity is 32 Bytes. L2 uses a Write-Back strategy; if it’s a Store instruction, it will always Hit the L2 Cache.
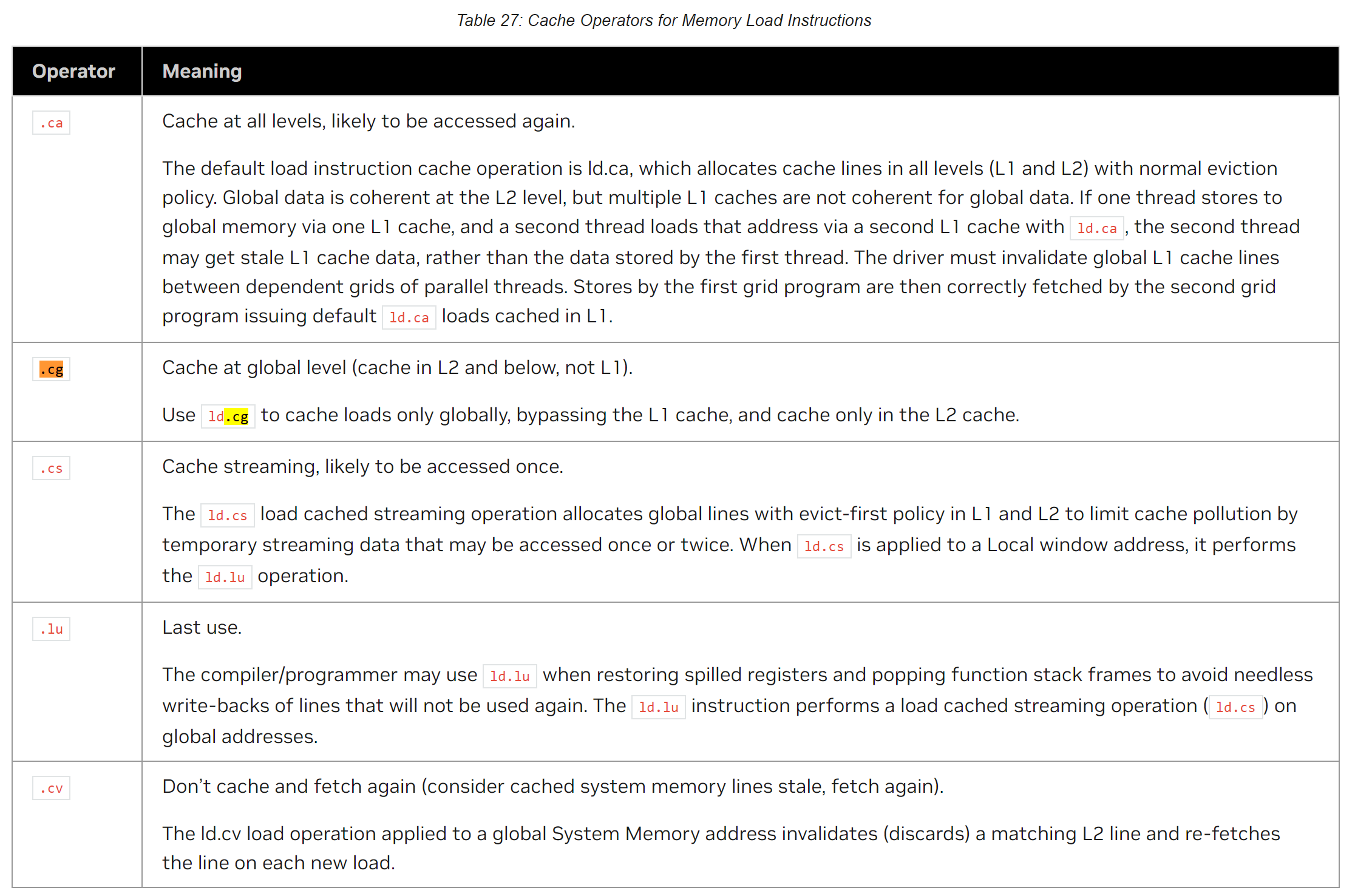
PTX Cache Operators:
You can finely control read and write behaviors using PTX Cache Operators.

2.2 Special Memory: Texture / Constant / Shared Memory
- Texture Memory: Features an on-chip read-only cache, highly optimized for 2D data structures (spatial locality). However, its on-chip cache lacks a broadcast mechanism; multiple Threads accessing the same address will cause multiple accesses, degrading performance.
- Constant Memory: Features an on-chip cache with low latency and supports broadcast operations, making it ideal for scenarios where all Threads read the same constant.
- Shared Memory: Extremely low-latency, programmable on-chip memory.
- Advantage: A Cache Miss severely interrupts the instruction pipeline in the SM. Shared Memory loading usually occurs during Kernel initialization, where long latencies can be perfectly hidden through Warp Context Switching.
- Pitfall: It provides high concurrency by dividing memory into Banks. When writing code, you must carefully design the memory Stride to avoid multiple Threads accessing the same Bank simultaneously, which causes serialization (Bank Conflict).
2.3 Memory Consistency and Fences
In complex concurrent programming, Instruction Reordering is the norm. To guarantee data visibility, we must use Memory Fences.

Classic Scenario: Partial Sum Accumulation across Blocks
|
|
Without __threadfence(), the update to count might be reordered before the write to result, causing the final Block to read an incorrect (unwritten) partial sum.
Proxies and Asynchronous Operations: In modern architectures, normal memory accesses are called Generic Proxies, while asynchronous copies (Async Copy) use different Proxies. Memory operations between different Proxies are unordered and require an explicit Proxy Fence to establish Memory Ordering.
3. Practical PTX Inline Assembly
When standard C++ APIs cannot generate the most efficient low-level instructions, or when we need to access specific hardware registers, we turn to PTX inline assembly.
3.1 Basic Syntax and Reading Timers
The basic format of PTX inline assembly includes the assembler template, output operands, input operands, and a Clobber List. For example, reading the internal clock register of an SM (in Clock Cycles):
|
|
To get a globally consistent time across all SMs (in nanoseconds), you should use %globaltimer.



3.2 Two Major Pitfalls of Compiler Optimization
Compilers are extremely smart; you must be careful when using inline assembly:
Pitfall 1: Optimized away as a Pure Function
If the compiler thinks your asm statement has no side effects (like reading a clock), it might extract the asm outside a loop to execute only once.
- Solution: You must use the
volatilekeyword, telling the compiler: “Every time execution reaches here, you must generate this instruction exactly as is.”
Pitfall 2: Memory reads/writes are reordered or cached If the assembly code implicitly modifies memory (i.e., not explicitly listed in the output operands), the compiler might not know the memory has changed and will continue using stale values cached in registers.
- Solution: Add a
"memory"Clobber List after the third colon.This acts as a Compiler Fence, forcing the compiler to flush dirty register data back to memory before executing the assembly, and to reload data from memory afterward.1asm volatile ("..." : : : "memory");

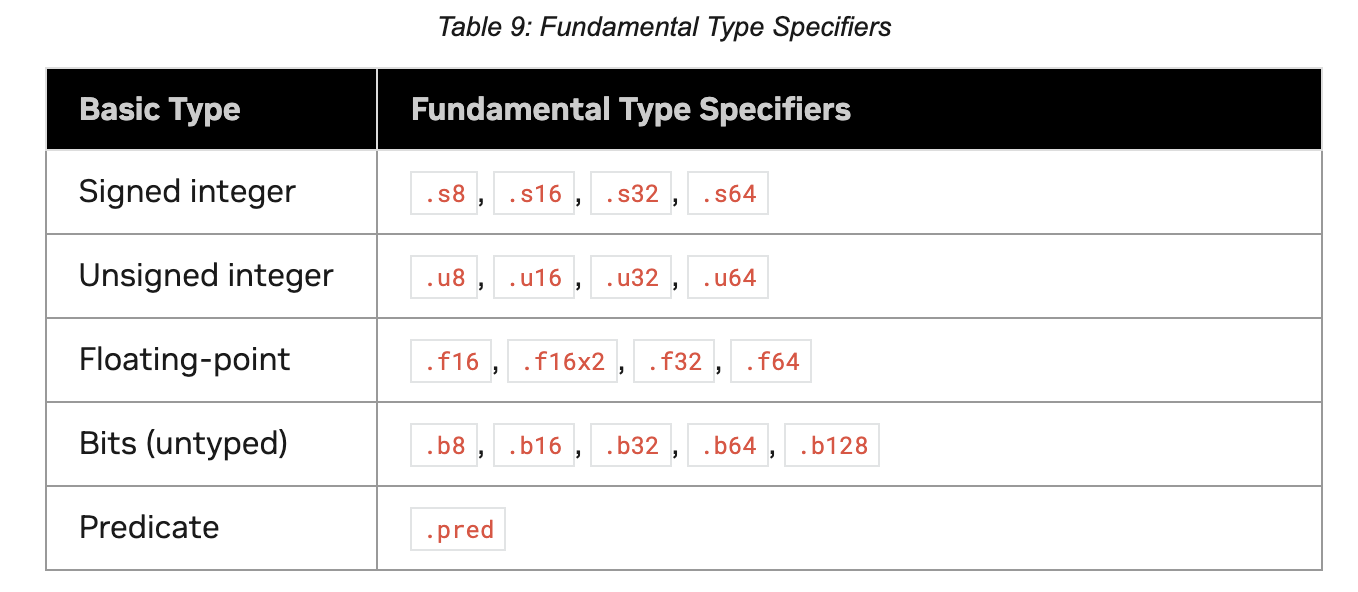
3.3 Register Modifiers and Type Conversion
In PTX inline assembly, register types and modifiers are crucial:
Difference between = and +:

3.4 Memory State Space
CUDA provides multiple memory spaces (e.g., Generic, Global, Shared), which can be determined and converted through specific APIs.

4. Frontier Features of the Hopper Architecture (H100)
The NVIDIA Hopper architecture introduces several revolutionary features designed specifically for large models and deep learning.
4.1 DPX and WGMMA Instructions
- DPX Instruction Set: Introduces Dynamic Programming instructions specifically to accelerate algorithms like Smith-Waterman (gene sequence alignment).

DPX Instruction Set - WGMMA (Warp-Group MMA): Hopper introduces a coarser-grained Tensor Core invocation compared to Ampere’s
mma.sync. Four consecutive Warps (128 threads) form a Warp Group.


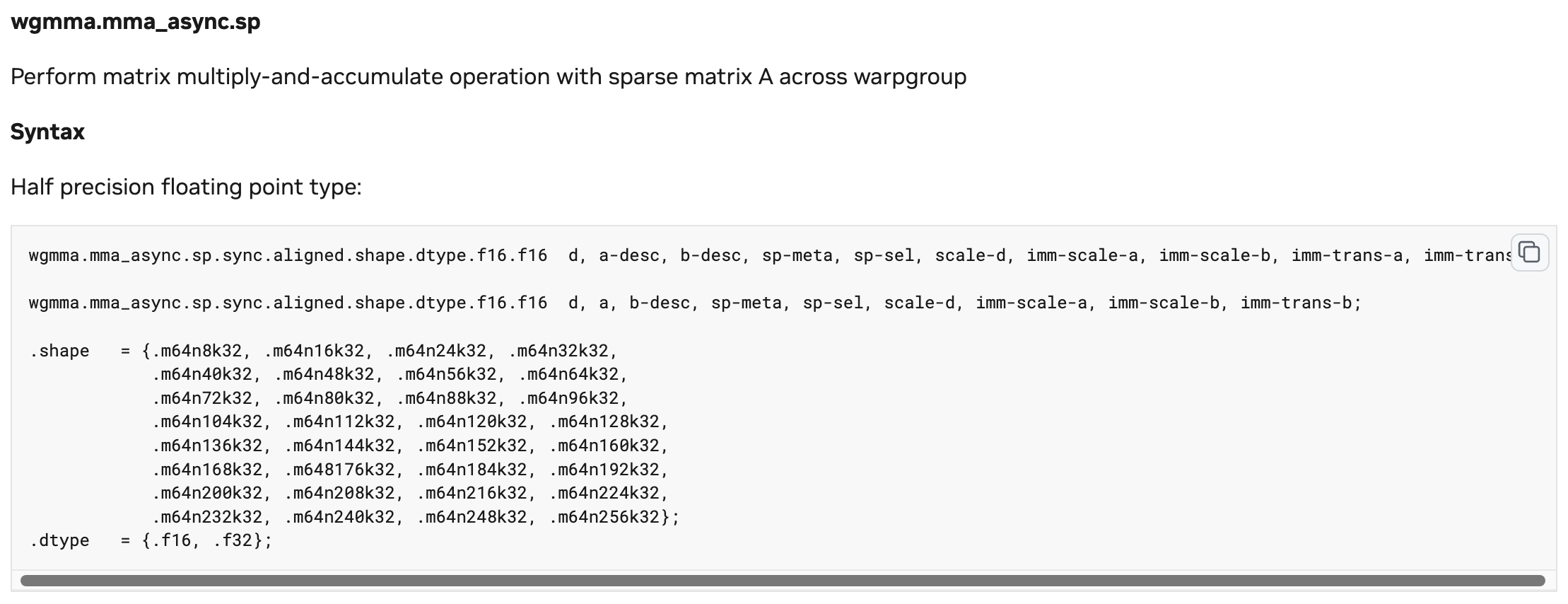
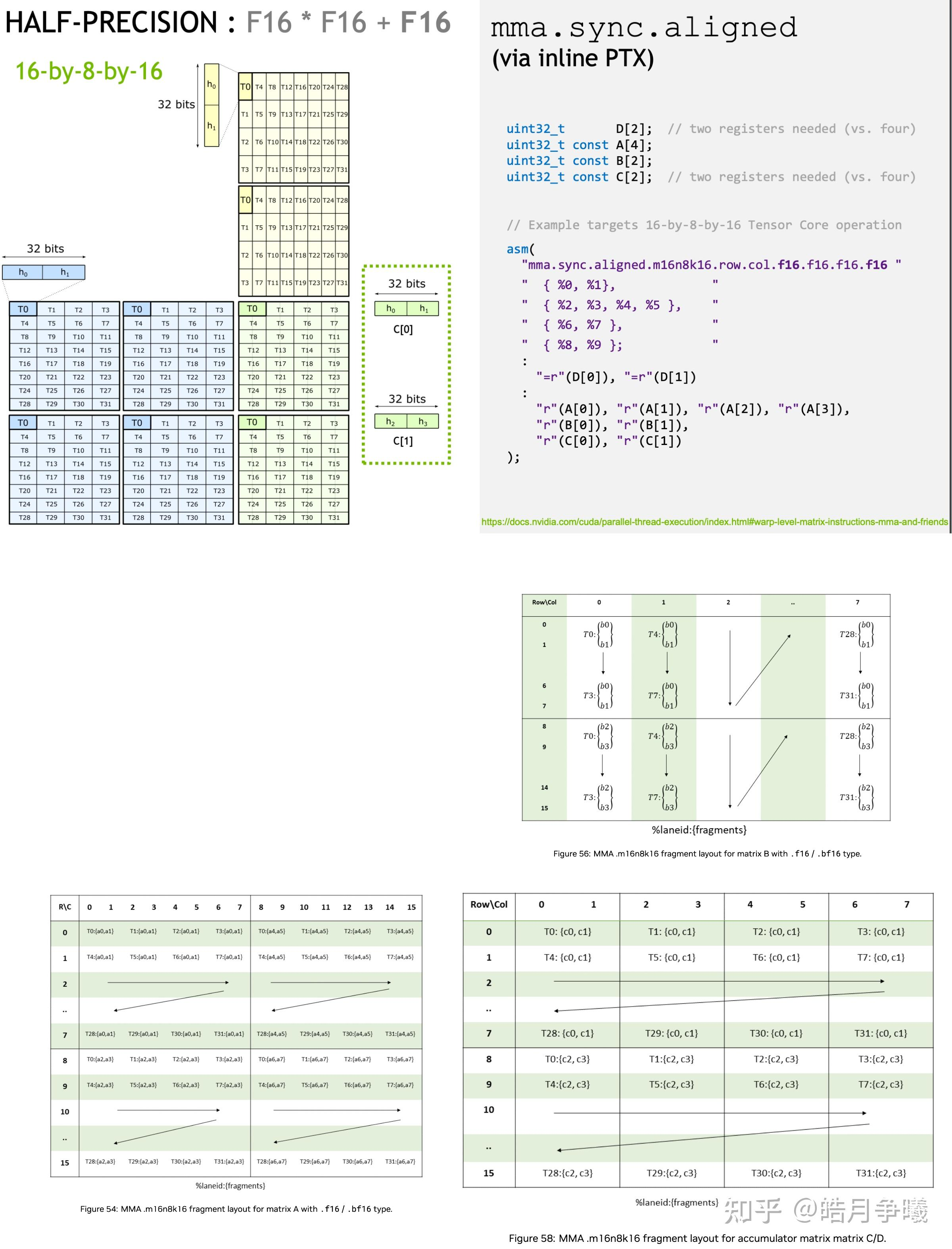
- Data Placement: The result matrix D must be in registers; however, input matrices A and B can reside directly in Shared Memory. This design drastically reduces the instruction overhead of loading data from Shared Memory into registers.
4.2 TMA (Tensor Memory Accelerator)
TMA is the core asynchronous memory access engine of the Hopper architecture. It allows the program to perform large-block asynchronous copies of multi-dimensional tensors between Global Memory and Shared Memory without consuming SM registers or instruction issue bandwidth.
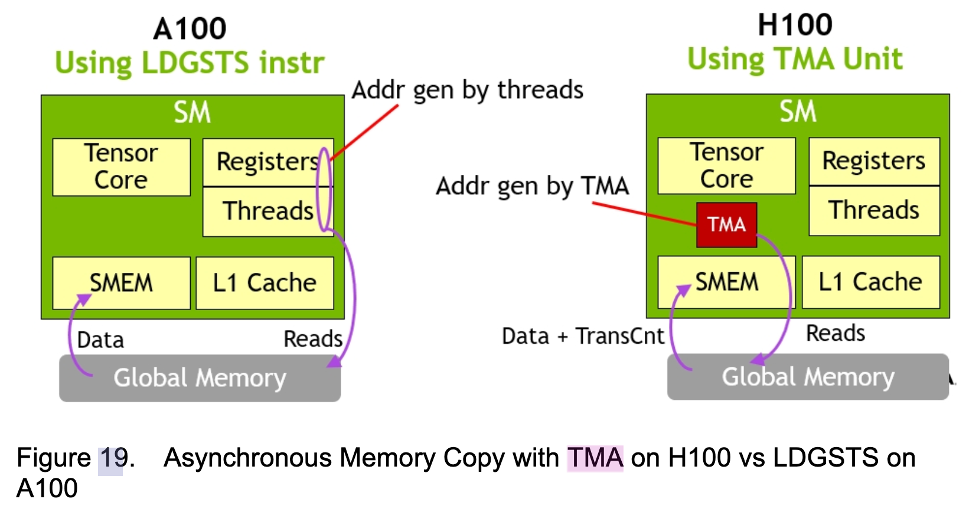
-
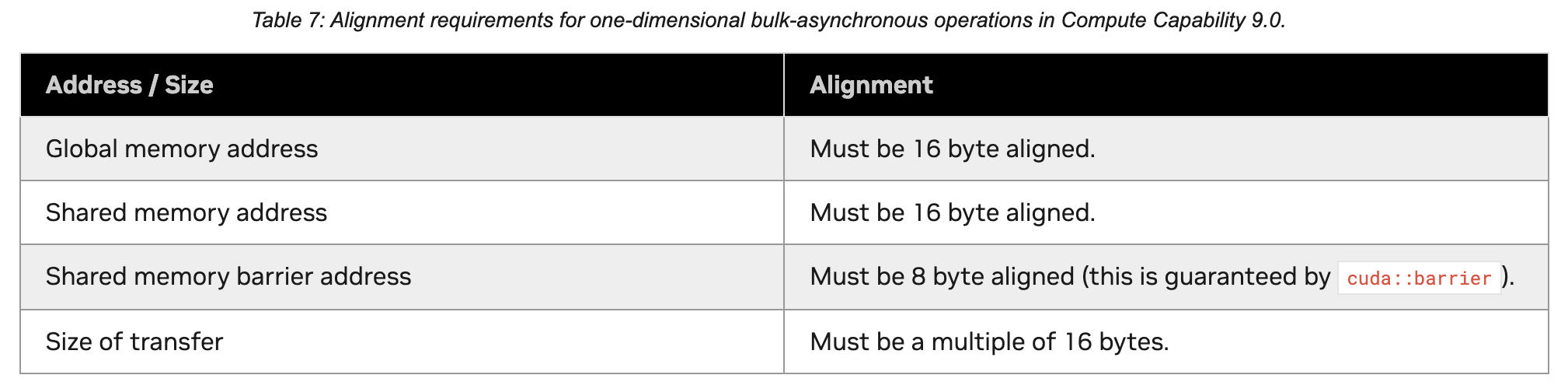
Alignment and Size Requirements:
- Size Requirements: The amount of data handled by a bulk asynchronous operation must be a multiple of 16 Bytes.
- Alignment Requirements: Whether in Non-tensor or Tensor mode, TMA enforces extremely strict memory alignment requirements (see figures below).
TMA Non-Tensor Alignment
TMA Tensor Alignment
-
Asynchronous Completion Mechanisms: Because TMA is entirely asynchronous, threads can perform other computations after initiating a copy, but there must be a mechanism to confirm when the copy is complete. Hopper provides two mechanisms:
- Mbarrier-based mechanism: Based on a hardware multicast barrier (mbarrier). Threads wait on an mbarrier until the TMA hardware signals arrival.
- Async-group mechanism: The traditional asynchronous copy group mechanism.
(Note: The appropriate mechanism should be used depending on the scenario. The official documentation regarding source and destination addresses for
Shared::clustermight contain confusing errata and should be verified with actual code testing.)
TMA Mbarrier Mechanism
Async-group Mechanism
-
Descriptor: TMA operations no longer require passing cumbersome pointers and strides. Instead, a TMA Descriptor (containing metadata like tensor dimensions, sizes, and strides) is created on the Host side, and the Device side directly uses this descriptor to initiate the copy.
TMA Descriptor



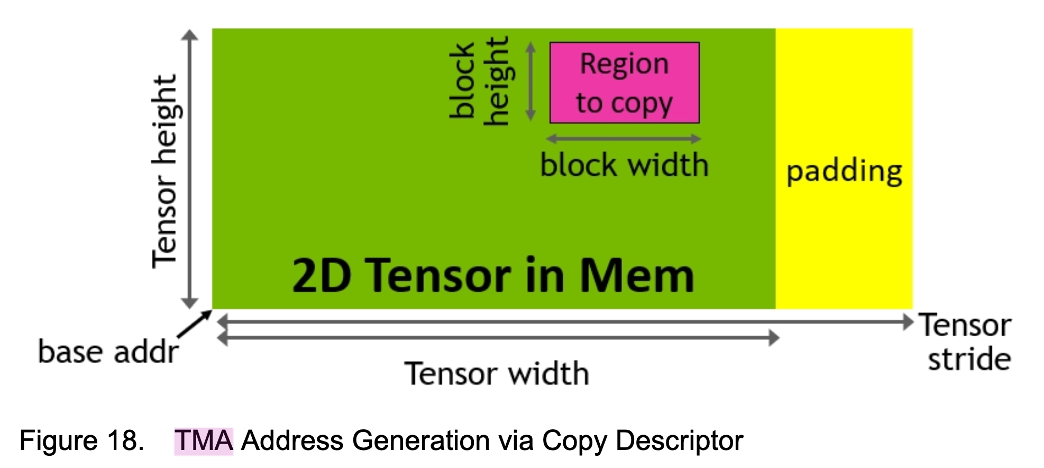
(Micro-benchmark Observation: When using TMA, statically allocated Shared Memory often performs better than dynamically allocated Shared Memory, which may be related to the underlying L2 Cache throughput mechanisms.)
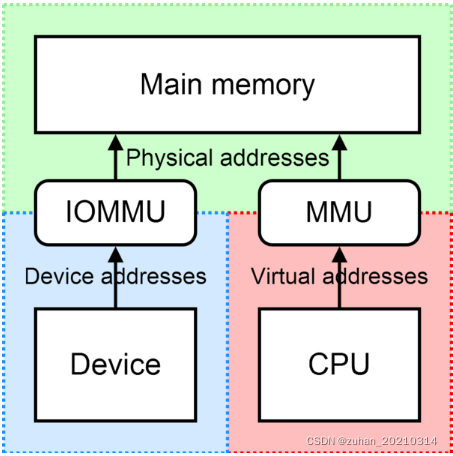
5. Supplementary Knowledge: DMA and IOMMU
When understanding low-level memory transfers, DMA (Direct Memory Access) and IOMMU (Input-Output Memory Management Unit) are unavoidable concepts.
6. Tips: C++ Template Instantiation
When writing CUDA code, if the template definition (.cu file) and invocation (.cpp file) are in different places, compilation will fail because the template parameters are unknown. In this case, Explicit Instantiation is required in the .cu file.


Conclusion
This concludes our CUDA Micro-benchmark Series.
From the compilation toolchain (nvcc, ptxas), Nsight Compute profiling, and Warp scheduling analysis in the first part, to hardware limit testing methodologies (FLOPS, Bandwidth), memory consistency, PTX inline assembly, and the cutting-edge TMA/WGMMA asynchronous features of the Hopper architecture in this part.
We hope these two articles serve as a hardcore reference guide for deeply understanding low-level GPU architectures and writing CUDA code with ultimate performance.